Linux CUDA Inference
Linux CUDA Inference
The system requires a CUDA-related runtime environment, the installation of the CUDA driver and TensorRT support library, and the acquisition of model files. The Linux verification version is Ubuntu 20.04.6 LTS x86_64.
Ubuntu Turn Off Kernel Auto Update
The installed driver is related to the operating system kernel. If the operating system kernel is updated, the driver will become invalid. Therefore, it is necessary to disable automatic kernel updates.Take Ubuntu 20.4 as an example.
sudo systemctl disable --now unattended-upgrades
sudo systemctl status unattended-upgrades
sudo vi /etc/apt/apt.conf.d/20auto-upgrades

cat /etc/apt/apt.conf.d/20auto-upgrades
APT::Periodic::Update-Package-Lists "0";
APT::Periodic::Unattended-Upgrade "0";
Install CUDA Driver For Linux
The CUDA driver comes with its own GPU driver, so there is no need to install the GPU driver separately before installing the CUDA driver.The currently used version of CUDA is cuda_11.8.0_520.61.05_linux.run.
You can enter the following link to download https://developer.nvidia.com/cuda-downloads
You can also directly click the link below to download:
After downloading, refer to the following commands to install it. Install the GPU driver during installation.
sudo ./cuda_11.8.0_520.61.05_linux.run
If the installation fails, you can replace tmpdir and install again.
sudo ./cuda_11.8.0_520.61.05_linux.run --tmpdir=/home/user/tmp
Linux Tensorrt Support Library Installation
Contact technical support to obtain the tensorrt.tar.gz package, and extract the package to /opt/tensorrt. The final directory structure is as follows:

Installation Of Model Files
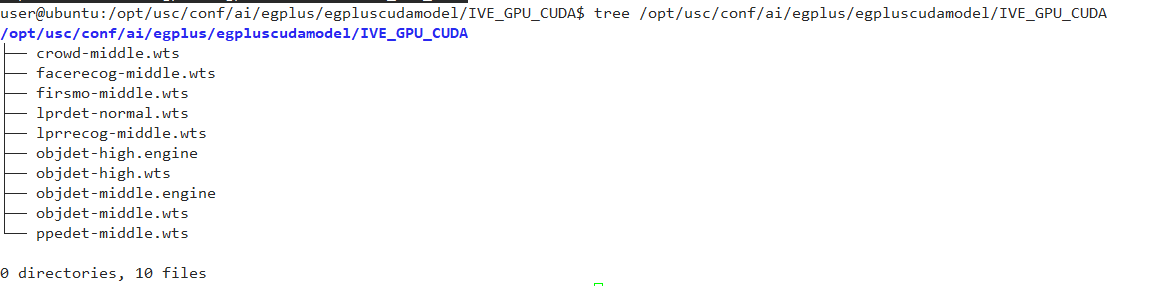
Contact technical support to obtain the model file package egplus.zip, and place the files in egplus/egpluscudamodel into the modules/ai/egplus/egpluscudamodel directory. The final directory structure is as follows:
After installation, restart the USC service, enter Analysis-》Settings-》Inference Service Configuration, and you can see the CUDA driver version and CUDA runtime version. Refer to the following figure:

The system will generate optimized models based on the GPU model when it is first started. After about 5 minutes, there will be a prompt in the Analyze-》Settings-》Inference Service Status. Refer to the following figure:
